
Implementation
HTTP Protocol and Web Server
HTTP 1.1
https://www.ietf.org/rfc/rfc2616.txt
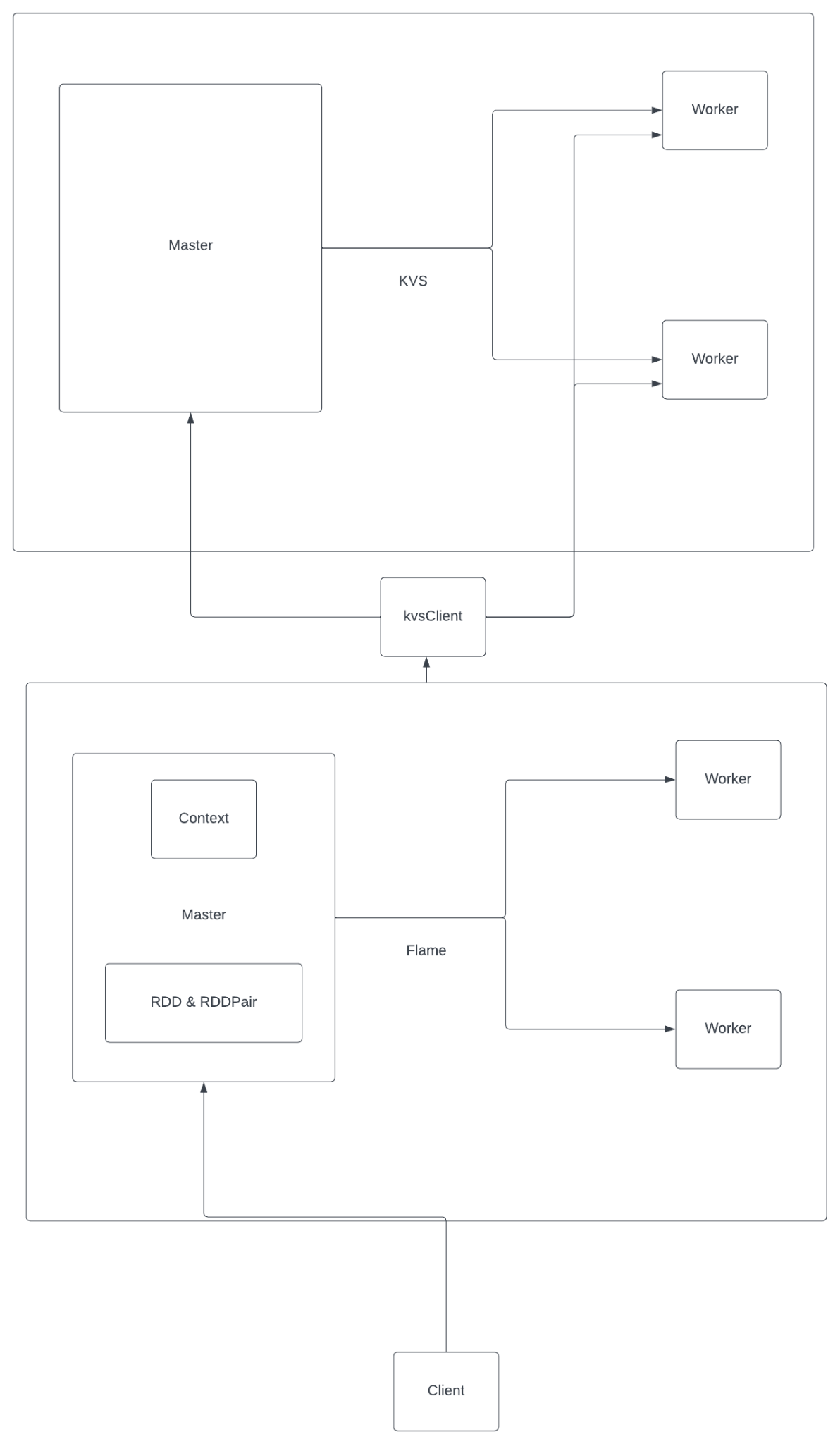
Distributed Key Value Store
RDD (Resilient Dataset)
the table that represents an RDD R := {v 1 , v 2 , . . . , v n } should have n rows; row #i should have an arbitrary but unique key and a column called value, which should contain v i . The keys should be at least somewhat random, so the table will be spread roughly evenly across the workers.
Pair RDD
The table that represents a PairRDD P := {(k 1 , v 1 ), (k 2 , v 2 ), . . . , (k n , v n )} should have as many rows as there are unique keys in the RDD; the row for an RDD key k should have k as its KVS key, and a column with a unique name for each value v j , where (k, v j ) ∈ P ; the value in that column should be v j A row in kvs can be parsed as many Pair RDDs.
Flame: Distributed Data Analysis Framework

Page Rank
- Load the data (PageRank): make (u,”1.0,1.0,L”) pairs, where L is a comma-separated list of normalized links you found on the page with URL u. We’ll call this the “state table” below.
- Compute the transfer table: For each pair (u,”r c ,r p ,L”), where L contains n URLs, compute n pairs (l i ,v), where v = 0.85 · r c /n. In other words, each of the pages that page u has a link to gets a fraction 1/n of u’s current rank r c , with the decay factor d = 0.85 already applied.
- Aggregate the transfers: adding up all the v i from the many P (u,v i ) pairs for each page u
- Update the state table: At this point, we have two PairRDDs: the old state table and an aggregated transfer table, both with the page URL as the key. We need to move the “new” rank from the latter to the former. To do this, first invoke join, which will combine the elements from both tables by URL, and concatenate the values, separated by a comma. This is not yet what we want – there are more fields in the join result than in the original state table – so you’ll have to follow up with another flatMapToPair that throws out the old “previous rank” entry, moves the old “current rank” entry to the new “previous rank” entry, and moves the newly computed aggregate to the “current rank” entry. This is also a good opportunity to add the 0.15 from the rank source.
- Iterate, and check for convergence: Put the code so far (after the initial load) into an infinite loop; at the end of the loop, replace the old state table with the new one, and then compute the maximum change in ranks across all the pages. This can be done with a flatMap, where you compute the absolute difference between the old and current ranks for each page, followed by a fold that computes the maximum of these. If the maximum is below the convergence threshold, exit the loop.
TF-IDF
- Load the crawler data. Extract and clean words from page body.
- For each distinct set of words from body, count the number of occurences of a word from the particular page body.
- Add distinct words into a persistent table, ‘index’, with unique words as key. For value, add a string concatenated with the hashed url and number of word occurences, e.g. ahzxghtoiu:1 (meaning there is 1 occurence of word in hashed url of ahzxghtoiu).
- Once all words are processed for all crawler data, calculate the IDF value by retrieving the occurrences of words that occur in different pages. The formula used to calculate TF-IDF in our case is log normalization-IDF, which is (1 + log f_t,d) * log (N/n_t), where f_t,d is the term frequency in a particular page, N is the total number of unique words in the index, n is the number of documents that contain the particular word/term.
** Note: IDF values are only calculated for query words, i.e. the value will be generated when the query comes in.